
tg-me.com/knowledge_accumulator/86
Last Update:
A Modern Self-Referential Weight Matrix That Learns to Modify Itself [2022] - поговорим о странном
Существуют совсем альтернативные обучающиеся системы, не использующиеся на практике. Эта концепция довольно забавная и будет использоваться в следующем посте, поэтому давайте о ней поговорим.
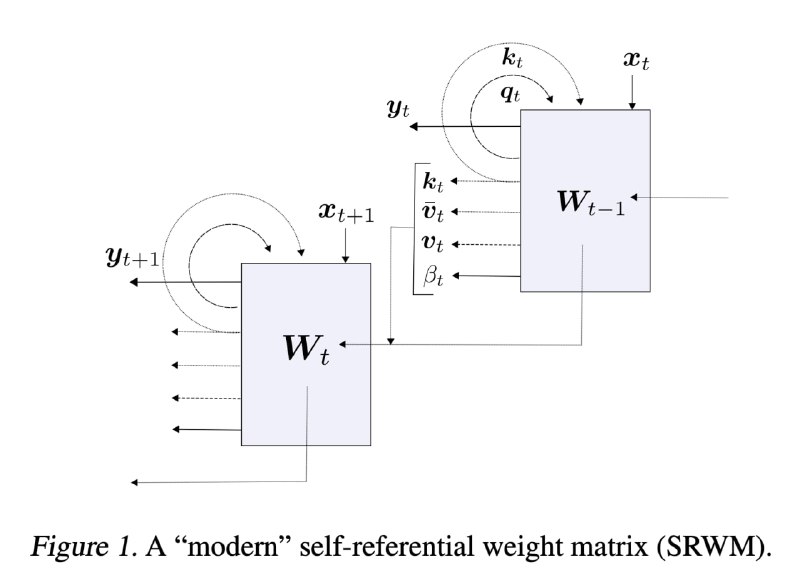
У нас есть матрица весов W. На каждом шаге она получает на вход какой-то вектор x. Результирующий вектор Wx разбивается на части y, k, q, b.
- y - это выход модели
- k, q и b - величины, использующиеся, чтобы обновить матрицу W. В расчётах там используется внешнее произведение векторов k и Wq, чтобы получить сдвиг для матрицы W, b используется в качестве learning rate. Всё немного сложнее в реальности, но примерно так.
Таким образом, в одной матрице зашито всё - и веса, и обучающий алгоритм этих весов. Всё будущее поведение системы задаётся только инициализацией матрицы W.
Вы спросите - нахрена это надо? Расскажу, как в принципе это может работать.
Данная матрица может быть полноценным few-shot learning алгоритмом. Чтобы её натренировать, мы сэмплируем из датасета с картинками N объектов из K классов, подаём эти N*K образцов и ответов в систему по одному, а затем учимся предсказывать тестовые сэмплы, бэкпропом пробрасывая градиенты и обновляя инициализацию матрицы W. Так делаем много раз, и со временем W на новой задаче начинает неплохо работать. Но не лучше топовых few-shot подходов.
Настоящий взрыв мозга с этой штукой я расскажу в следующем посте, а пока всем хороших выходных 😁
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/86